


SEonthebeach 2019. Día 1: la automatización como factor común
09 julio 2019
El evento SEO con más personalidad de nuestro país volvió a reunir a los mejores profesionales del posicionamiento web y marketing digital en la Región de Murcia
La séptima edición de uno de los eventos de la comunidad SEO más importantes, SEonthebeach, dejó satisfechos a todos los asistentes, por la genial combinación de calidad de contenidos, el buen ambiente y la magnífica localización. Nuevamente, fue el incomparable entorno de La Manga del Mar Menor el que acogió, durante los pasados 14 y 15 de junio, dos jornadas de ponencias interesantísimas.
Con un maestro de ceremonias como Sico de Andrés, “desorganizador” del congreso, la diversión, pero también la información de calidad sobre el mundo del SEO, estaba asegurada.
Screaming Frog con Mj Cachón
Mj Cachón, experta en SEO y marketing online, inauguró la primera jornada con una charla titulada “Screaming Things”. Tal y como adelantaba el título, la presentación se centraba en el uso de la herramienta Screaming Frog SEO Spider para hacer tareas SEO. En concreto, se centró en dos cuestiones: cómo agilizar los análisis SEO más habituales y cómo realizar análisis SEO más avanzados.
Entrando ya en el manejo del programa, recordó a los asistentes 2 opciones que para ella son clave y que permiten agilizar los análisis: Guardar configuración (File > Configuration > Save As…) y Programar rastreos (File > Scheduling) con las configuraciones que hemos guardado previamente.
 Opciones clave de Screaming Frog según Mj Cachón
Opciones clave de Screaming Frog según Mj Cachón
Respecto a la primera parte de la presentación, fue haciendo paso a paso un ejemplo de cómo monitorizar errores en una web, explicando cómo configurar el programa, guardar esa configuración, programar el rastreo de forma periódica y seleccionar las opciones de exportación. Con esta información se puede hacer seguimiento a muchos tipos de tareas SEO, como por ejemplo revisión de datos estructurados, mejoras de enlazados internos o revisión de indexabilidad.
En la parte más avanzada explicó en primer lugar cómo hacer un backup de posibles incidencias SEO para posteriormente contar cómo analizar a la competencia mediante Screaming Frog. Para ello, hay que utilizar 2 opciones clave adicionales: búsqueda personalizada (Configuration > Custom > Search) y extracción personalizada (Configuration > Custom > Extraction). Puso varios ejemplos de extracciones personalizadas: extraer el número de elementos de cada categoría de producto de una web, extraer el precio y los más vendidos (sin stock) y extraer el descuento de los productos rebajados; para un blog sacar los autores, categorías y etiquetas. En todos los casos puntualizó que hay que guardar la configuración y programar el rastreo con la frecuencia que queramos (día, semana o mes).
Para finalizar, indicó que con lo visto hasta ese punto ya se podría analizar cualquier web que se quisiera, Google, el BOE, Amazon, etc., mostrando un par de ejemplos: extraer los datos (nombre, nº de estrellas y precio) de los productos más vendidos de Amazon y el seguimiento de una SERP de Google.
Más automatización SEO de la mano de Alfonso “Mou” Moure
El segundo en subir al escenario fue el cántabro Alfonso Moure,que habló sobre la automatización en el mundo del SEO.
Alfonso comenzó con varios ejemplos que, realizados de forma manual, conllevan mucho tiempo de trabajo y espera, tales como consultas complejas a los archivos log del servidor o analizar el comportamiento del bot de Google (o cualquier buscador) sobre los diferentes tipos de URL de nuestra web. Estos ejemplos le llevaron a plantear la pregunta: ¿qué se necesita para solucionar este tipo de tareas ahorrando tiempo y esfuerzo? A la cual respondió con cuatro puntos:
- Disponibilidad total de datos en tiempo real.
- Evitar trabajos repetidos.
- Compartir los resultados con el resto del equipo.
- Dedicar el tiempo a la toma de decisiones, no a pelear con las herramientas.
Estos procesos automáticos se pueden preparar tanto en nuestro propio ordenador como en un servidor o, como recomendaba Alfonso, mediante servicios Cloud Serverless, los cuales se utilizan únicamente cuando se necesitan. Las características de estos servicios son:
- Despliegue fácil y sin incompatibilidades.
- Ahorro de energía.
- Menor coste.
- 100 % desatendido.
- Fácil de conectar con otros servicios.
Como ejemplo de servicios Cloud Serverless mostró los de Google Cloud, con las siguientes herramientas:
- Cloud Serverless Functions, para automatización y procesamiento.
- Cloud Storage, para almacenamiento.
- Cloud BigQuery, para exploración y consulta.
- Data Studio, para visualización.
 Servicios de Google Cloud explicados por Alfonso Moure durante su presentación
Servicios de Google Cloud explicados por Alfonso Moure durante su presentación
Con esas herramientas más Scrapinghub para realizar el rastreo de la web (es similar a Screamingo Frog pero vía web), propuso varios ejemplos tales como un historial de cambios realizados en la web, con historial completo, una recopilación de archivos log de servidor o una visualización y seguimiento de impactos recopilados de forma autónoma.
Para el desarrollo técnico recomendó que, si no tenemos los conocimientos suficientes, lo mejor es buscar desarrolladores que programen y configuren las herramientas para tener los datos que realmente necesitas para hacer tu trabajo; en este punto hasta llegó a citar 3 plataformas online donde poder encontrar profesionales: Upwork, LinkedIn y Freelancers.
Para finalizar, el ponente recordó que lo importante es concentrarse en lo que uno mejor hace y no dejarse llevar por el miedo a no estar a la última. Además, expuso de forma clara y concisa, cuánto dinero necesitamos invertir en dicha infraestructura para el scraping y análisis de datos, poco más de 10 € al mes para 110 Gb de datos de rastreo y 25 millones de impactos desde archivos log. Esta fue, sin duda, una de las charlas más rigurosas, mejor planteadas y brillantes del congreso.
El SEO vitaminado de Álvaro Peña de Luna
Después de la clase magistral de Alfonso, llegó el turno de Álvaro Peña de Luna, Co-CEO y director de SEO de iSocialWeb y Virality Media. Este experimentado SEO presentó un caso real de un proyecto montado desde cero para la presentación de SEOonthebeach, dentro de un sector competido y para el que sólo contaban con 6 meses (desde que recibieron la invitación para el congreso).
Entrando en materia, comenzó explicando las características que habían elegido para la elección del sector:
- Que Google no esté presente en el sector para no tener que competir con él.
- Que tenga un alto potencial de escalado de tráfico e internacionalización.
- Que presente diferentes vías de monetización.
- Que no dependa únicamente de una fuente de tráfico.
- Que puedan generarse productos relacionados.
- Que permita una salida comercial si no funciona.
El primer punto del anterior listado no lo cumplieron, ya que al tener poco tiempo no les importaba competir con Google. Para ver los datos de potencial de un mercado, Álvaro puso unas capturas de la herramienta Market Finder de Google. Sobre las diferentes vías de monetización, el ponente comentó que cuantas más haya mejor y nombró las siguientes: AdSense, CPA, venta de leads, venta de productos y venta de tráfico.
Siguiendo con las características del sector, se presentó el perfil de tráfico directo, referido, de búsqueda y social de varios competidores, viendo cómo en ese sector predominaba el tráfico de búsqueda y el directo (el de marca). Sobre la generación de productos relacionados puso como ejemplos, más allá del canal web, una aplicación móvil, skills de Alexa, addons para navegadores y aplicaciones para webs de terceros.
A continuación, se presentaron una serie de contras a la hora de elección de nicho y Álvaro desgranó cómo los habían solventado. En primer lugar, que la competencia sea baja o moderada, aunque en el caso del ejemplo entraron en un sector de alta competencia. Que la barrera de entrada económica y técnica sea un poco alta, ya que en su caso cuentan con un potente equipo técnico y una capacidad económica. Por último, hay que tener en cuenta los ataques de rentabilidad que se suelen dar por parte de los competidores en sectores con rentabilidades muy altas.
 Álvaro Peña de Luna dando su ponencia
Álvaro Peña de Luna dando su ponencia
Una de las principales fuentes de captación de tráfico fue Facebook porque ofrece un tráfico cualificado y de bajo coste y el ponente señaló que el tráfico es un pilar fundamental para el crecimiento de un proyecto. Las características ideales del tráfico son:
- Que sea real, relacionado con la página y que genere una buena experiencia de usuario.
- Que sea geolocalizado o que comparta idioma.
- Que sea constante y escalado.
La presentación continuó con la generación de los enlaces. Los puntos que se trataron de este aspecto fueron:
- Revisión de los perfiles de enlaces de la competencia para comprender la media del nicho (si presentan crecimientos constantes o tienen picos de creación de enlaces, por ejemplo).
- Generar una base de datos a partir de enlaces de pago, destacando la herramienta FuSEON Link Affinity, uno de los patrocinadores del congreso y cuyo propietario es el propio Sico de Andrés,
- Técnica del enlace caníbal, que consiste en conseguir un enlace comprado en la página de tu propia competencia (siempre que sea un medio digital, ya que todos suelen vender enlaces).
- Generar una base de datos propia de enlaces gratuitos categorizados.
- Técnica de los enlaces salientes, mediante la herramienta Ahrefs buscar vulnerabilidades que permitan colocar enlaces en las páginas que nos interesen.
Respecto a la generación de contenido y el volumen de direcciones URL, se optó por tener pocas direcciones URL e ir actualizando el contenido de las mismas, en lugar de generar direcciones URL nuevas para cada contenido. De esta forma, enviaban todo el tráfico a una única landing, evitaban canibalizaciones de Keywords y problemas de indexación y rastreo. También se mejoraba la arquitectura y el reparto de linkjuice.
A continuación, pasó a la parte de rentabilizar el proyecto. En este sentido, Álvaro comentó cómo empezaron a optimizar la publicidad, analizando las direcciones con mejor coste efectivo y enviando el tráfico ahí. Llegado un cierto volumen preguntó directamente a los usuarios qué eran lo que buscaban y a partir de ahí se facilitó la conversión. También se utilizó Landbot.io para montar un chatbot de contacto con los usuarios. Por último, habló de la mejora de los funnels de conversión, en este caso de calentamiento de leads mediante email marketing.
Con todo lo anterior, el proyecto llegó pronto a generar más de 150 € diarios de AdSense, además de haber generado más de 20.000 euros en ventas. A su vez, a los 5 meses les llegó una oferta de compra por valor de 15.000 euros.
En la última parte de la presentación, explicó cómo seguir optimizando el SEO para captar más tráfico sin aumentar costes, mejorar las secciones peor posicionadas y aumentar el alcance del SEO. Aquí habló de utilizar las notificaciones push para enviar a los usuarios de nuestra base de datos a la web, mediante la aplicación Truepush. Respecto a la mejora de las secciones peor posicionadas, el consejo que dio fue el de revisar la semántica de las diferentes secciones por si algunas estuvieran más alejadas del resto y, si fuera así, corregirlo.
Con todo esto los resultados del proyecto fueron que, tras 6 meses, se contaba con más de 53.000 visitas diarias y más 11.000 de ellas de tráfico orgánico.
Después de esta didáctica ponencia, se hizo una pequeña pausa para tomar una cerveza fresca, mientras el animador de turno motivaba a los asistentes con una serie de juegos y actividades.
¡Que lo haga otro! Automatizaciones SEO a cargo de Iñaki Huerta
Con la energía recuperada por parte del público era el turno de disfrutar de una nueva charla. Iñaki Huerta, el experimentado SEO, director de la empresa IKAUE volvió a la carga con la automatización, dividiendo la charla en 3 tipo de automatizaciones, según las realicemos mediante:
- Nuestro ordenador
- Servicios en la nube
Para el primer tipo de automatizaciones, las que realizamos usando nuestro ordenador, recomendó la herramienta Robotask. Esta herramienta permite la grabación y creación de tareas personalizadas paso a paso. También se encarga de ejecutarlas cuando lo programemos. Las tareas que realizó Iñaki durante su chara fueron:
- Subir sitemaps de forma automatizada.
- Navegar y copiar datos de los que necesitamos hacer seguimiento cada cierto tiempo, como por ejemplo descargas de palabras clave sugeridas, datos de cobertura de Google Search Console o datos de otras herramientas SEO (Sistrix, Seobox, Semrush, etc.) sin necesidad de acceder vía API.
- Informes periódicos a medida, por ejemplo, con capturas de pantalla de dashboards que no podemos exportar.
Para los servicios en la nube el ponente también se centró en una herramienta, en este caso Integromat, aunque comentó las características de otras más conocidas como IFTTT o Zapier. Los motivos que dio para decantarse por esta herramienta es que es muy intuitiva y cuando te haces a ella es la más versátil. La forma de trabajar con ella es mediante flujos de trabajos que se definen con drag&drop, siendo casi como programar, pero mediante clics y formularios. Los ejemplos que puso de esta herramienta fueron:
- Insertar las nuevas publicaciones de la competencia en Google Analytics.
- Enviar informes a Slack y al móvil.
- Alertas cuando algún dato de Google Analytics suponga un problema para el negocio.
- Aviso si una página crítica deja de funcionar.
- Alerta de bajada de visibilidad en Sistrix (mediante la API de Sistrix).
 Iñaki Huerta en SEonthebeach 2019
Iñaki Huerta en SEonthebeach 2019
Para las automatizaciones con Google presentó la aplicación Google Apps Script, es Javascript pero en lugar de usar el objeto de la ventana del navegador utiliza objetos Google. Las ventajas de esta aplicación para Iñaki son:
- Comodidad en la programación (programación en la propia web sin instalar nada, código integrable con Google Sheets, amplia comunidad en Stack Overflow, etc.).
- Accesos directos mediante llamadas a funciones y objetos ya creados (a todos los servicios de Google Apps, a muchos otros servicios de Google y otras utilidades de scripting).
- API para lanzar y gestionar los scripts desde otros servicios.
Ricardo Tayar, método, testing y personalización
Ricardo, ponente habitual en SEonthebeach, vino este año a La Manga del Mar Menor a hablar de método, testing y personalización. Comenzó explicando que el testing es una parte del CRO, pero que sólo utilizando esa parte ya se pueden obtener mejoras de conversión en los proyectos, como ejemplificó mostrando varias gráficas de Google Analytics de webs reales. Al principio, lo que quiso dejar claro es que se utiliza el testing para que las decisiones de cambios diseño y de negocio se apoyen en datos y se elimine la opinión en esas situaciones.
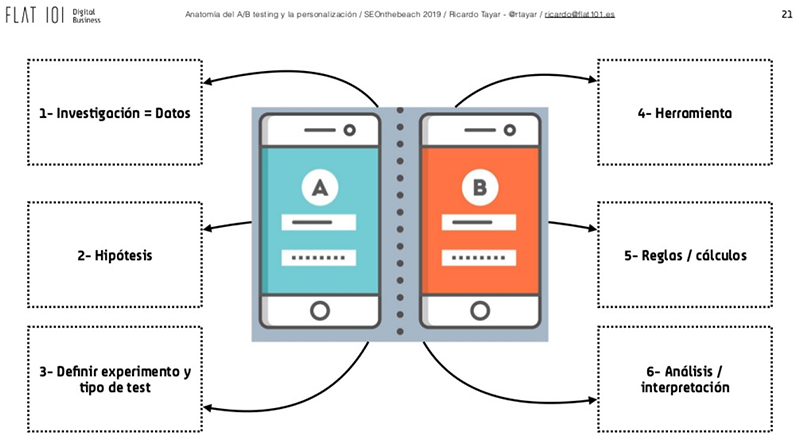 Partes mínimas que debe tener un test A/B según Ricardo Tayar
Partes mínimas que debe tener un test A/B según Ricardo Tayar
La charla continuó presentando el método científico como base para la resolución de problemas:
- Observación
- Inducción
- Hipótesis
- Experimentación
- Demostración
- Tesis
Entrando en materia incidió que los datos son el punto de partida para localizar ineficiencias. Respecto a esto distinguió 3 tipos de datos principales en los que fijarse: navegación, consumo de contenidos y transacción. Y recordó que, además, es importante segmentar dichos datos por dimensiones, tales como:
- Tipo de dispositivo.
- Fuente de tráfico.
- Tipo de usuario (nuevo, recurrente, login, cliente, etc.).
- Rutas de conversión.
- Tipos de objetivos o eventos.
Si los datos cuantitativos no ofrecen información suficiente podemos recurrir a datos cualitativos, por ejemplo:
- Funcionamiento en diferentes países.
- Mapas de calor de elementos de menú.
- Mapas de calor de uso de formularios.
Para la formulación de hipótesis citó los criterios de Kerlinger:
- Debe expresar una relación entre 2 o más variables.
- Debe ser clara y específica, evitando términos vagos o ambiguos.
- Debe implicar una posible prueba empírica.
Y respecto a las variables que aparecen indicó los 3 tipos que se encuentran:
- Variable independiente: la que vamos a modificar en nuestra hipótesis. Por ejemplo, CTA, imagen de un producto, imagen de cabecera, etc.
- Variable dependiente: la que creemos que sufrirá un cambio como consecuencia de la modificación de la variable independiente. Por ejemplo, número de clics, ratio de añadir al carrito, tiempo de permanencia, etc.
- Variables intervinientes: las que debemos controlar durante el test para asegurarnos de que el escenario es lo más estable posible durante la prueba. Por ejemplo, presupuesto de AdWords, envío de newsletters, etc.
Ricardo ofreció a los asistentes una fórmula estándar para la definición de hipótesis en entorno digital:
Para [grupo o segmento de usuarios], si [cambio que pretendemos realizar] se producirá [efecto que prevemos] porque [explicación racional], lo que impactará en [métricas sujeto de medición].
Seguidamente, explicó de forma rápida 3 tipos de test:
- A/B, donde se cambia sólo un elemento en cada una de las versiones dejando el resto igual, lo que permite una atribución clara.
- Multivariante, se cambian varias variables a la vez y se elige la versión que mejor ha funcionado.
- Multipágina, se prueban diferentes páginas con múltiples cambios, no se puede atribuir el éxito o el fracaso a una única variable.
En cuanto a las herramientas, comentó Google optimize e Instapage para la iniciación en el test A/B, así como los plugins Nelio testing, Thrive Headline Optimizer y AB Press Optimizer para WordPress.
A continuación, comentó cómo calcular el número de muestras que son necesarias para dar por bueno un test. Utilizando el porcentaje de conversión esperado y el porcentaje mínimo de cambio que se espera detectar se obtiene la significancia estadística y el número de muestras necesarias. Estos cálculos se pueden realizar de forma online mediante las herramientas A/B Test Sample Size Calculator de Optimizely y Sample Size Calculator de Evan's Awesome A/B Tools.
Una vez realizado el test, toca analizar e interpretar los datos, para ello Ricardo mostró varios ejemplos reales hechos con Optimizely, tanto de tests con resultados positivos como negativos, y volvió a recordar la necesidad de repetir las pruebas para que los datos no sean fruto del azar o de variables externas. También recordó que lo que funciona para una sección de una web o un tipo de producto no tiene por qué funcionar para otro.
Como último punto, habló de que casi todas las herramientas de test están evolucionando para ser herramientas de personalización, que muestren a cada usuario, según una serie de variables, diferentes versiones de nuestra web, bien con un contenido diferente, una navegación distinta o cualquier funcionalidad que queramos.
Ismael El Qudsi, Internacionalizar no es traducir tu web al inglés
Después de la pausa para la comida, siguieron las ponencias con el turno de Ismael El Qudsi, CEO de Internet Republica y Socialpubli.com.
Ismael comenzó hablando de emprender un negocio tratando los siguientes puntos:
- Errores con los socios. Tales como no firmar un pacto de socios, regalar acciones o cambiar acciones por servicios (diseño, abogado, etc.).
- Pensar en no tener jefe, cuando el cliente es el jefe.
- Problemas con los clientes: no firmar un contrato de prestación de servicios, no acordar un pago del 50 % por adelantado y tener unos tiempos de pago altos (crea problemas de caja ya que no se tiene dinero, aunque el trabajo esté facturado).
- Poner precio a tu servicio.
- Problemas con los bancos. Se soluciona teniendo al menos 2 bancos.
- Buscar financiación. Vías posibles:
- FFF (Family, fools and friends).
- Business Angels. Se les considera una fuente de “dinero inteligente” porque además de dinero suelen aportar conocimiento a la empresa.
- Crowdfunding.
- Incubadoras.
- Aceleradoras
- Fondos de inversión.
- CDTI (para empresas de I+D) o ENISA (financia el 50 % de la inversión).
- Impuestos: IVA, IRPF, Seguridad Social, Impuesto de Sociedades e Impuestos para sacar dinero del país si tenemos localizaciones en el extranjero.
La ponencia siguió desde la perspectiva de que ya tenemos claro que vamos a internacionalizar. Entonces, ¿a qué mercado nos dirigimos? Para la investigación de mercados podemos echar mano del ICEX, una entidad pública que promueve la internacionalización de empresas españolas.
 Ismael El Qudsi en su presentación para SEonthebeach 2019
Ismael El Qudsi en su presentación para SEonthebeach 2019
Ya tenemos el mercado decidido, el siguiente paso, según Ismael, es darnos a conocer. Para ello es necesario invertir en publicidad, normalmente SEM, pero también es una buena idea la asistencia a ferias o eventos. Respecto a la relación con los medios, nos aconsejaba contar con una buena agencia o una persona interna para el área de Comunicación.
También es muy importante la localización, tener en cuenta la cultura local a la hora de publicar imágenes y textos. Y si tenemos una plataforma global, que el contenido sea lo más neutro posible para que llegue a cualquier cultura, en cualquier estación del año, etc. También una buena traducción, así que podemos olvidarnos de Google Translate.
Por último, destacó la importancia de tener algún mentor o socio donde vayas a montar tu proyecto, ya que ayudará mucho en todos los puntos anteriores.
Nacho Mascort enseña programación para SEO
Continuaba la jornada con Nacho Mascort, SEO specialist de Softonic. Nacho tenía como objetivo motivar a los SEO a lanzarse al mundo de la programación y comenzó dando una serie de motivos para empezar a programar siendo SEO:
- Mejor comprensión de la web e Internet.
- Independencia de herramientas de terceros.
- Automatización.
- Aumenta el volumen de datos con los que trabajar, ya que ciertas herramientas fallan al procesar muchos datos.
- Mejora de la comunicación con los desarrolladores.
 Nacho Mascort comenzando su ponencia
Nacho Mascort comenzando su ponencia
Por la popularidad entre la comunidad de desarrolladores y por el interés que generan, los mejores lenguajes para empezar actualmente a programar son Javascript, tanto para la parte de usuario (front) como para la parte de servidor (back), y Python para back y análisis de datos.
Así pues, Javascript y Python fueron los lenguajes que utilizó Nacho durante los ejemplos y explicaciones de la presentación. Para comenzar, explicó una serie de conceptos básicos de programación, tales como variables, tipos de datos, operadores, condicionales, iteraciones o funciones.
A continuación, enumeró algunas opciones donde podemos ejecutar el código que creamos:
- En la consola de comandos (DevTools de Chrome) o la consola del sistema operativo.
- Usando archivos y ejecutándolos en consola o mediante un IDE (entorno de programación) que tenga integrada una consola.
- Para Python también podemos usar los notebooks (entornos web de programación interactiva, como Google Colab).
También hizo una pequeña mención a 3 IDE
- Sublime Text.
- Visual Studio Code (uno de los más populares).
- Atom.
Para acabar con el código, explicó 4 casos prácticos de programación en el mundo SEO:
- Comprobar si una URL es la canonical.
- Revisión de migración de un dominio (comprobación de direcciones URL, comprobación de valores de etiquetas y comprobación de redirecciones).
- Devolver la tendencia de palabras clave de Google Trends para un número ilimitado de palabras (normalmente el límite es de 5 por consulta).
- Realizar las comprobaciones de etiquetas SEO de una página (on page) de forma automática.
El punto y final lo puso señalando la importancia de la programación en el mundo del SEO, remarcando que lo que hoy puede ser una ventaja competitiva en el futuro puede ser un requisito básico, tal y como muestra el hecho de que en el propio SEonthebeach cada vez haya más presentaciones que incluyen elementos de programación, sobre todo en los casos de automatización.
Cómo sacarles jugo a las patentes de Google, con Iván García
La charla de Iván García, SEO freelance y fundador de RockROI, estuvo vertebrada en 3 puntos:
- Qué dicen las patentes sobre temáticas relacionadas con el SEO.
- Ideas y conceptos que ya sabemos o intuimos, pero que están en las patentes.
- Consejos o ideas que podemos extraer de esas patentes.
Lo primero a tener en cuenta es que Google afirma que porque tenga una patente sobre algo no significa que lo esté utilizando. Sin embargo, analizando sus patentes obtenemos una visión de la forma de pensar de los trabajadores y creadores del buscador.
Las fuentes que utiliza Iván para la búsqueda de patentes son Google patents, papers universitarios, Patent & trademark office US, el blog SEO by the Sea y buscando en buscadores de patentes el nombre de ingenieros de Google.
A continuación, entró a explicar varias métricas de las que se encontraba información en las patentes:
- Tiempo de visualización de un documento (vídeo, audio, página web, etc.). Se aumenta la puntuación en los resultados de los recursos con tiempo de visualización largos y se disminuye en los que tienen tiempos cortos. Como idea, indicó el intentar alargar los tiempos de visualización de nuestros recursos.
- Page Speed. Según las patentes, el tiempo de carga puede basarse en una medida estadística del tiempo de carga de diferentes dispositivos en los que se puede ver la página o el recurso. El consejo en este aspecto es utilizar PageSpeed Insights, GTmetrix o herramientas similares para mejorar la velocidad de carga.
- Edad del dominio. En lugar de utilizar la fecha en la que se ha registrado, se usa la de la primera vez que ha sido rastreado o que ha sido enlazado. Tambien se indica que se utiliza los enlaces a un documento, así como el tiempo en que se han enlazado y su crecimiento para posicionar. Lo que sugiere Iván es crear contenido que sea perdurable, ya que si los usuarios continúan enlazándolo, Google seguirá valorándolo positivamente.
- Quality score. Las patentes hablan de consultas asociadas o relacionadas a una página, que denomina “site querys”. Estas consultas son las que se hacen añadiendo el nombre de marca a la consulta o con el comando site, por ejemplo. También en las que un alto porcentaje de usuarios acaban en una página, a la que acaba asociada dicha consulta. Estas consultas van determinando el quality score del sitio. La recomendación en este punto es trabajar el sitio para ofrecer respuestas de calidad a los usuarios y que así vayamos teniendo “site querys” relacionadas con nuestra web, lo que aumentará nuestro quality score.
- Peso de un enlace basándose en la probabilidad de clics. En este caso, Iván comentaba que el peso de un enlace se basa en la probabilidad de clics en lugar de los clics realmente obtenidos. También se valora el contenido alrededor del enlace y el anchor text. Así, el consejo en este punto es poner nuestros enlaces importantes en zonas de contenido, ya que tienen mayores probabilidades de clic respecto a otras zonas como pies de página o barras laterales.
- Frases relacionadas. Las páginas con más frases relacionadas se posicionan mejor. Google mira las consultas para las que una página es óptima y ve qué frases significativas aparecen respecto a páginas que posicionan para el mismo término. Las indicaciones a este respecto fueron observar las SERP de los términos que queremos posicionar y añadir frases similares en nuestro contenido o también usar esas frases como anchor text.
- Keywords en encabezados, títulos y listas. Si una lista tiene un encabezado, se considera que todos los elementos de esa lista están a la misma distancia del encabezado. Lo mismo ocurre con las palabras contenidas bajo el encabezado principal de una página y de otros elementos como las tablas. Aquí proponía que nos aseguráramos de que estos elementos fueran descriptivos del contenido que encabezan y que incluya palabras clave y frases relacionadas.
- Términos contextuales. Los términos que tienen diferentes significados, como por ejemplo banco (peces, dinero, mobiliario), son recopilados junto con términos contextuales que muestren el significado que se pretendía. Con ello se crea una base de conocimiento que indica la intención de búsqueda concreta. Lo que podemos trabajar en este punto es la terminología del contexto, cuanto más ricos y complejos sean los términos de contexto, mejor entenderán los buscadores la intención de búsqueda a la que responden.
- Contenido incoherente. Mediante la construcción de modelos de lenguaje se determina qué contenido es incoherente. Si se detecta este tipo de contenido en una página se baja su valoración de posicionamiento. Se recomienda eliminar este tipo de contenido de nuestra página web, el cual puede llegar por malas traducciones, comentarios con faltar ortográficas o gramaticales, redacciones pobres, etc.
- Baja calidad. La baja calidad se muestra mediante enlaces salientes en zonas de poco peso (pie de página, barra lateral, sitemap, etc.). También hay un filtro de diversidad que contabiliza como un solo enlace cuando se enlaza un mismo recurso desde muchas páginas. Si un sitio no llega a un mínimo de quality score se le puede considerar de baja calidad. En ese caso, sus páginas bajarán su posicionamiento para los términos de búsqueda. Así pues, debemos controlar los enlaces en zonas de bajo peso y controlar la calidad general del sitio: contenido duplicado, linkbuilding, arquitectura pobre, etc.
- Freshness. La patente intenta determinar qué consultas son más aptas para mostrar contenido más reciente. Esto es cuando hay un volumen importante y reciente de artículos de blog, noticias, menciones en redes sociales (Twitter), consultas de noticias de esa búsqueda y usuarios que en esa búsqueda eligen noticias en lugar de contenidos orgánicos. La medida a tomar es analizar la SERP y ver si ofrece muchos resultados de noticias o artículos recientes. Si es así, debemos actualizar nuestro contenido o crear contenido reciente.

Iván García durante su presentación
- Páginas de SERP y consultas. Aquí se habla de página de autoridad como la que contiene contenido de confianza, preciso y fiable. También que la autoridad varía con la query, así podemos tener autoridad para “marketing digital” y no tenerla para “restaurantes en Murcia”. También se nombran aquí las site querys que vimos en el punto de quality score. Para tener controlado este punto, se mandaba revisar la guía de los quality raters de Google (de la cuál hablaremos en el artículo del segundo día en la charla de Chuiso) e intentar posicionar consultas relacionadas con la marca o el dominio.
- Bases de datos que responden a consultas. Google consulta las búsquedas dentro de un sitio para ver si son similares a las consultas que él recibe. Si son similares y de calidad, puede posicionar esos resultados directamente en sus SERP. Iván destaca que esto aplica a páginas como buscadores de viajes o páginas de anuncios clasificados.
- Clics en las SERP. Las patentes hablan de analizar el feedback del usuario y asociarlo a la calidad del documento. Estos datos se comparan con modelos que ya tiene Google y modifica en base a ello la posición de un resultado en la SERP. Al final, se trata de mejorar el CTR en la página de resultados y para ello hay muchas maneras conocidas de captar la atención del usuario: mediante el título, descripción, favicon, usando fechas, llamadas a la acción, reconocimiento de marca, etc.
- Ranking basado en parámetros biométricos. El ponente comenzó este punto diciendo que no cree que esta patente se esté utilizando actualmente. Se trata de tener en cuenta la reacción del usuario respecto a los resultados mostrados. Si los resultados no son del agrado del usuario, podrían ser degradados en un futuro para esa consulta. Esta reacción se mediría mediante la cámara frontal de un teléfono inteligente y podría analizar elementos como la dilatación de la pupila, el movimiento del ojo o la velocidad del parpadeo. Aquí habría que quedarse en que nuestro resultado debe satisfacer al usuario.
- Repetición de clics y duración de visitas. Se cuenta como repetición de clics cuando un usuario está buscando y entra a una página, si luego vuelve a la búsqueda y acaba en el mismo dominio, aunque haya usado otra keyword. También cuenta el tiempo de estancia en la web. Las páginas con contenido que se actualiza y que hace que los usuarios vuelvan y las que tienen contenido que generan sesiones largas de visitas son las que se verían favorecidas por este punto.
- Modelo CAS (Clics, Atención y Satisfacción). Es una patente que se basa en 3 modelos. El modelo de atención, que valora la reacción del usuario ante la SERP; el modelo de clic, que valora la posición del contenido en la SERP y su CTR; y el modelo de satisfacción, aquí se introducen nuevas formas de valoración, no solo que se haga clic en tu resultado, sino por ejemplo que ofrezcas la propia respuesta a la consulta del usuario en la SERP. Por tanto, se nos presenta un cambio significativo en la SERP, donde ya no solo hay que buscar el clic, sino también la atención y satisfacción del usuario ofreciendo respuestas directamente en el título, descripción, imagen, etc.
- Actividades sospechosas para mejorar ranking. Aquí Iván habló de una función rank-transition que Google usa para cambiar de forma aleatoria la posición de una página y analizar la reacción. Esta función busca páginas que tengan actividades sospechosas, como keyword stuffing, para mitigar sus efectos en las posiciones del ranking. La manera de no verse afectado por esto es seguir las Guidelines de Google y evitar manipular los resultados de búsqueda.
- Quality raters. Las páginas web se valoran del 1 al 5, tanto de forma global como cada página individual. También se pueden marcar como pornográfica, de marca, inválida, etc. La regla a seguir aquí es no crear sitios enfocados 100 % al SEO, ya que pueden acabar siendo valorados por un humano que tiene que encontrar una web navegable y de apariencia positiva.
La charla de Iván fue, sin duda, una de las más técnicas y con más densidad de información del congreso.
César Aparicio presentó Link Building: pasado, presente y un futuro disruptivo.
El Link Building sigue siendo una herramienta primordial en el posicionamiento, de ahí la importancia de esta ponencia por parte de César Aparicio, Seo cofundador de Safecont.
La primera idea que ofreció el ponente es que, en sitios grandes, el link building puede ayudar a la recuperación de direcciones URL que han dejado de estar o que nunca han estado posicionadas, lo cual puede traer una gran cantidad de tráfico orgánico de nuevo a nuestra web.
Hay que priorizar objetivos, ya que, si bien es importante traer cuanto más tráfico mejor, es mucho más importante el valor que tiene ese tráfico. También tenemos un ejemplo de prioridad en las palabras claves competidas, donde tenemos que valorar el esfuerzo que nos supone competir por cada una de ellas frente a la rentabilidad que podemos obtener.
A continuación, César dijo que frente a las diferencias de datos entre herramientas, aboga por dar prioridad a los datos que ofrece Google Search Console.
También advirtió que hay que llevar cuidado con las “chapuzas” porque quizá pueden funcionar durante un tiempo, pero también te pueden llevar a una penalización de enlaces artificiales por parte de Google. Como consejo explicó la “parábola del link building y las aletas de bucear” que viene a decir que quien quiere ahorrar acaba pagando el doble, ya que primero compra lo más barato y, una vez que no le ha funcionado eso, acaba comprando lo que tiene más calidad y es más caro.
Sobre el perfil de enlaces contó que hay que estar siempre alerta por si recibimos un ataque de SEO negativo. Como consejo recomendó usar FuSEON Link Affinity.
En la última parte de su ponencia, César habló de futuro. Comenzó utilizando la Ley de gravitación universal para formular una nueva manera de organizar Internet. De esta forma, las direcciones URL de “menor masa” se encontrarían más próximas a las de “mayor masa”. A su vez, a mayor fuerza gravitacional tendríamos mayor proximidad con la consulta.
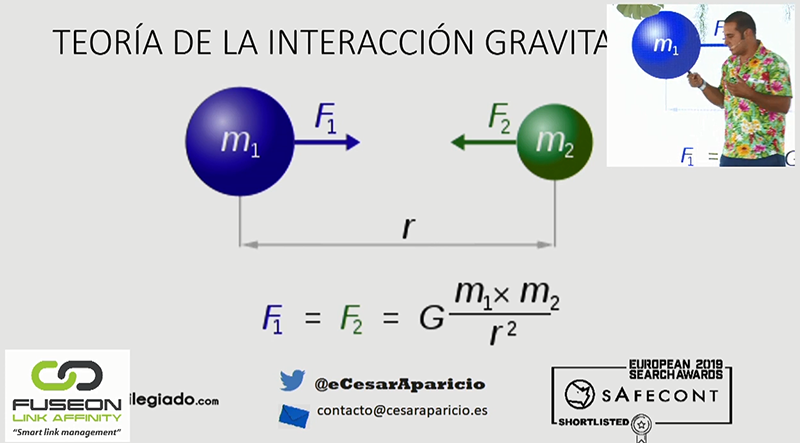 César Aparicio explicando la Ley de gravitación universal
César Aparicio explicando la Ley de gravitación universal
Para finalizar, destacó que los enlaces fueron, son y parece que serán un punto clave en el funcionamiento de Internet, al menos en el futuro más cercano. Así pues, el link building continúa siendo un factor esencial en el posicionamiento. No obstante, los límites de la tecnología avanzan continuamente.
Descifrando las cifras… Google Search Console, Lino Uruñuela
El cofundadorde Funnel punk,Lino Uruñuela, cerró la primera jornada de SEOnthebeach desentrañando la herramienta Search Console, un servicio gratuito de Google para webmasters que permite comprobar el estado de indexación de sus sitios en Internet.
Comenzó indicando que hay algunos elementos que en Search Console se muestran con la misma posición, aunque incluyan varias URL, estos son elementos como un bloque local, resultado de imágenes y vídeos, carruseles, etc. En bloques de carrusel, sólo se cuenta como impresión si es visible por el usuario. También recordó que cada vez hay más elementos en las SERP: respuestas web, artículos AMP, eventos, etc.
Para Lino una de las métricas más importantes de Search Console es el número de clics totales, ya que describe perfectamente la evolución de la web y cuánto se llega a los usuarios. Sin embargo, la posición media es una métrica que por si sola no indica nada, ya que no dice cuántas palabras clave tiene en cuenta o cuántas palabras son nuevas. Es una métrica que sí ofrece información interesante cuando se filtra para una única palabra clave, ya que se puede ver su evolución.
Por su parte, las impresiones es una métrica que nos puede dar pistas sobre direcciones URL con potencial para posicionar. Serían direcciones que han tenido muchas impresiones, pero en las que tenemos una posición baja.
A continuación, Lino explicó un cambio reciente a cargo de Google en Search Console y es que iban a consolidar los datos de las URL no canónicas a la URL canónica. Esto significa en la práctica que, si por ejemplo la web tiene una dirección para la versión de ordenadores y otra para la versión de móvil y la dirección canónica es la de ordenadores, en Search Console los datos saldrán solo con la URL de ordenadores e incluirá los datos de ordenadores y móviles, sin que se puedan saber cuáles pertenecen a unos y cuáles a otros.
En los datos de las gráficas de Search Console se presentan de vez en cuando incoherencias, como número de clics que se incrementan al aplicar un filtro. Esto no ocurre en los que se presentan en las tablas. Esto tiene que ver con una manera de calcular los datos que Google llama “por propiedad” y “por página”. Es por ello que Lino recomienda que usemos los segundos en nuestros proyectos.
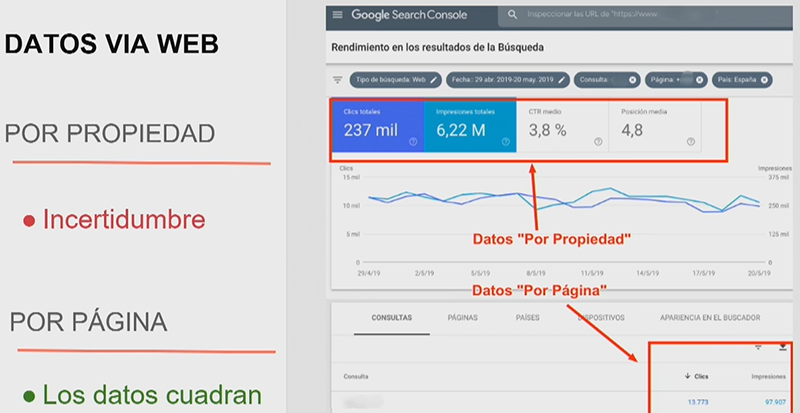 Explicación de los datos “por propiedad” y “por página” de Google Search
Explicación de los datos “por propiedad” y “por página” de Google Search
Para eliminar la incertidumbre que presenta la interfaz web de Search Console habría que acceder mediante la API. Lino explicó que él lo hace mediante el lenguaje PHP y con la base de datos ClickHouse. De esta forma, tendremos más datos y no estaremos sujetos a las restricciones de segmentación.
Lino terminó su presentación explicando cómo calcula Google la posición media de cada Keyword, que es mediante una media ponderada en la que los clics se ponderan con las impresiones.
Otros recursos interesantes de Posicionamiento Web


